December 23, 2025
GPT-5.1 vs Ministral-3 3B: Evaluating AI Newsletter Quality For Local AI Newsletter Generation
Evaluating OpenAI's GPT-5.1 and Mistral's Ministral-3 3B for automated newsletter generation based on content quality, clarity, formatting and inference speed using n8n Evaluations and LLM-as-a-judge.
Can a $0 local model running on your MacBook compete with OpenAI's GPT-5.1?
Every API call to a frontier model costs money and sends your data to a third party. Running models locally has always involved trade-offs—but recent small models have narrowed the gap significantly.
To measure the difference, I built a six-stage n8n workflow—news ingestion, relevance scoring, editorial decision, research, formatting, delivery—and ran identical experiments with two models: GPT-5.1 via API and Ministral-3 3B running locally on a MacBook Air (M3). Then I evaluated both using LLM-as-a-judge across five newsletter topics.
Result: GPT-5.1 leads on every metric, but the gap is smaller than expected.
| Metric | GPT-5.1 (Cloud) | Ministral-3 3B (Local) |
|---|---|---|
| Content Quality | 3.6 | 2.8 |
| Clarity | 4.6 | 4.2 |
| Formatting | 4.0 | 3.4 |
| Average | 4.07 | 3.47 |
| Runtime | ~1.5 min | ~10 min |
| Cost per run | ~$0.18 | $0 |
For some topics like crypto, the gap nearly disappears. Three workflow patterns make local models practical:
- Break tasks down — Multi-stage pipelines beat single mega-prompts
- Auto-correct JSON — Use additional LLM calls to fix malformed outputs
- Keep context short — Smaller inputs/outputs reduce memory pressure
Read on for the full workflow, evaluation setup, and what this means for your own AI automation.
Why Go Local?
Running a local model instead of calling an API has several advantages beyond cost:
The case for local:
- Cost: At $1.25 per million input tokens and $10.00 per million output tokens, GPT-5.1 adds up. In our workflow, we observed ~60k input and ~10k output tokens per run, costing roughly $0.18 per execution.
- Privacy: Your prompts and generated content stay on your machine. The workflow still calls external APIs for news retrieval and research enrichment, but the LLM reasoning happens locally.
- Resilience: Local models are immune to API outages (such as the two recent Cloudflare outages), model deprecations, and changes to system prompt handling or content policies (such as the changes in Sora 2 guardrails). You control the model version and configuration.
The trade-offs:
- Inference time: A 3B model on a MacBook processes requests sequentially rather than in parallel. In our tests, local execution took 6–7x longer than cloud API calls.
- Quality: The 3B model showed more difficulty adhering to prompt instructions, particularly in selecting articles that align with user-specified topics.
- Reliability: Local infrastructure introduces different failure modes, including memory limits and thermal throttling.
This post builds on my earlier work: building an AI newsletter introduced single-LLM digests, and the AI news agent added history-aware deduplication and editorial logic. This version extends the approach with a multi-stage pipeline that can run on either GPT-5.1 or a local 3B model with the same workflow—enabling direct comparison of quality and cost.
The Workflow

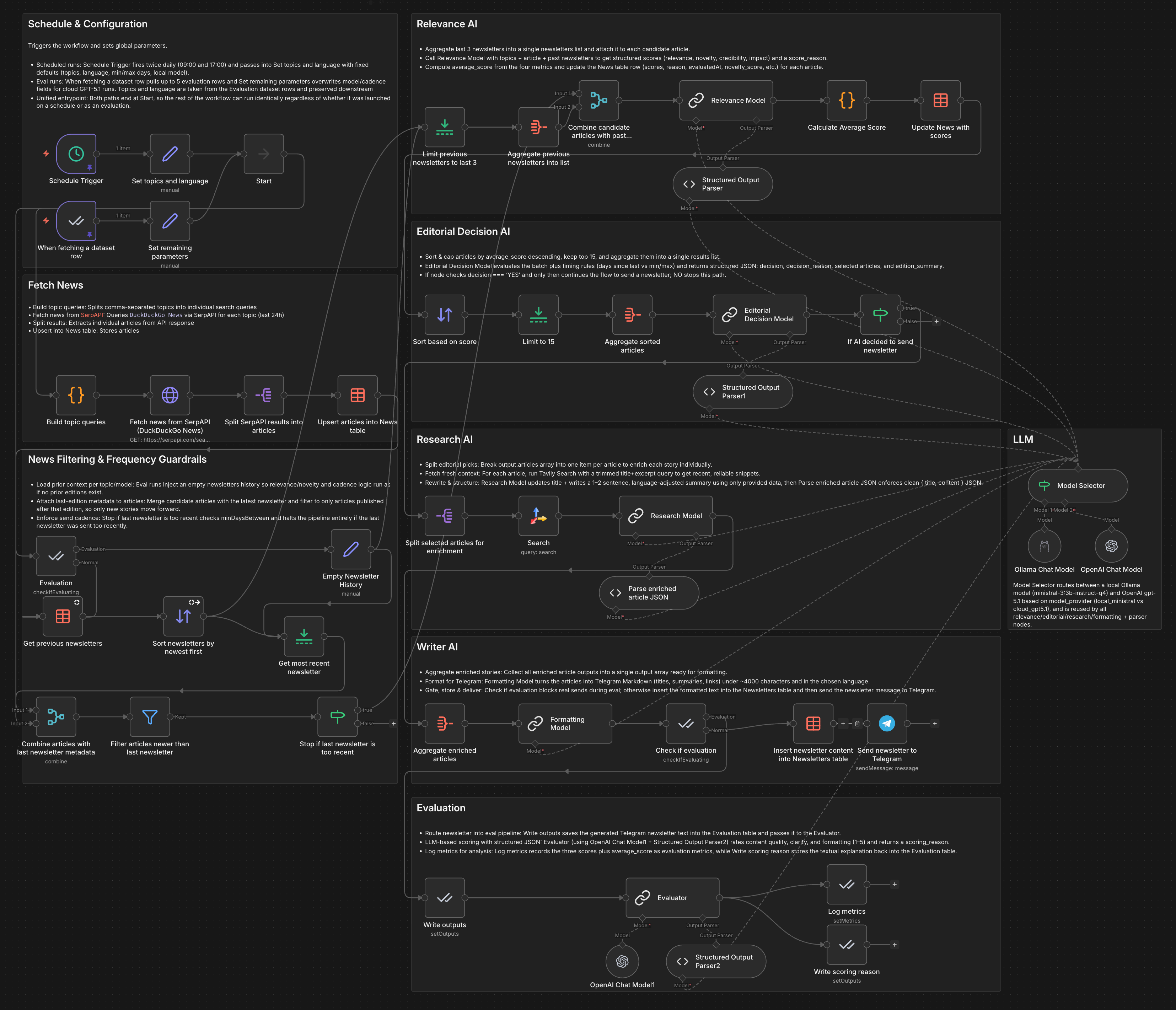
The workflow runs on a schedule (twice daily), pulls fresh news via SerpAPI, and only sends a newsletter when there's relevant content above a quality threshold.
Here's how the six stages work together:
1. News Ingestion
Fetches articles from DuckDuckGo News for each configured topic. Results are stored in an n8n data table using upsert logic to avoid duplicate entries.
2. Frequency Guardrails
Compares against your last newsletter. Too recent? The workflow stops. Too long since the last one? It forces a send even with weaker material. You control minDaysBetween and maxDaysBetween.
3. Relevance Scoring (LLM)
Each article gets scored 0–10 on four dimensions:
- Relevance — How closely does it match your topics?
- Novelty — Was this already covered in recent newsletters?
- Credibility — Is the source trustworthy?
- Impact — How significant is this development?
4. Editorial Decision (LLM)
The top 15 scored articles go to an "editor" that decides: Should we send today? If yes, it picks 3–5 diverse, high-impact stories. If no, the workflow exits silently.
5. Research & Enrichment (LLM + Tavily)
Selected articles get fact-checked and enriched. Tavily pulls fresh sources, and the LLM rewrites each into a concise, accurate summary.
6. Formatting & Delivery (LLM)
Everything gets assembled into Telegram-friendly Markdown (respecting the 4000 character limit), stored for future deduplication, and sent to your chat.
Key design choice: Each LLM call has a narrow, well-defined job. This decomposition makes a 3B local model viable—no single call requires complex multi-step reasoning.
All four LLM stages share a single Model Selector node, making it trivial to swap between GPT-5.1 and Ministral-3 3B via Ollama without touching the prompts.
Three Tricks to Make Local Work
Running a 3B model instead of GPT-5.1 requires workflow-level accommodations. Here's what made the difference:
-
Decompose into small cognitive tasks
A single "be my news editor" prompt would overwhelm Ministral-3 3B. Instead, each LLM call does exactly one thing: score relevance, decide yes/no, rewrite a summary, or format output. The workflow handles orchestration, not the model. -
Auto-correct malformed JSON
Small models produce malformed structured output more often. The workflow uses n8n'sautoFixoption on structured output parsers—if the first attempt fails JSON validation, it automatically re-prompts the LLM to fix it. This adds latency but significantly improves success rates. -
Keep context windows short
Instead of evaluating all news articles from SerpAPI at once, the workflow lets the LLM evaluate each article separately, leading to much smaller context and thus lower memory footprint when using Ministral-3 3B on your local machine.
The Experiment
The central question: how does a small, local, heavily quantized model (Ministral-3 3B at Q4_K_M) compare against a frontier model (GPT-5.1) for this specific task?
Evaluation Setup
n8n provides built-in Evaluations for running workflows with varied inputs and scoring the outputs. This enables controlled comparison between model configurations.
The evaluation dataset consists of five topic combinations spanning technical and lifestyle domains:
| ID | Topics | Language |
|---|---|---|
| 1 | AI, n8n | en |
| 2 | health, fitness, vegan diet | en |
| 3 | personal finance, investing, retirement planning | en |
| 4 | bitcoin, crypto markets, blockchain | en |
| 5 | productivity, habit building, deep work | en |
Each row is processed by the full workflow twice: once using GPT-5.1, once using Ministral-3 3B. The prompts and news sources remain identical—only the underlying model changes.
Scoring with LLM-as-a-Judge
Generated newsletters are evaluated using LLM-as-a-judge, where a separate model (GPT-5.1) scores each output on three dimensions:
- Content Quality (1–5): Alignment with requested topics, accuracy, and usefulness of information.
- Clarity (1–5): Readability, logical structure, and ease of comprehension.
- Formatting (1–5): Scannability in Telegram, structural consistency, and proper source attribution.
n8n's evaluation framework also logs execution time and token counts per run, providing data for cost and latency analysis out of the box.
Results
GPT-5.1 outperforms on all metrics—but the margin varies significantly by task type.
Can You Tell the Difference?
Before diving into the scores, test your intuition. Below are actual newsletter outputs from both models—can you guess which is which?
| Metric | GPT-5.1 | Ministral-3 3B | Gap |
|---|---|---|---|
| Content Quality | 3.6 | 2.8 | -0.8 |
| Clarity | 4.6 | 4.2 | -0.4 |
| Formatting | 4.0 | 3.4 | -0.6 |
| Average | 4.07 | 3.47 | -0.6 |
| Runtime | ~1.5 min | ~10 min | +8.5 min |
| Cost/run | $0.18 | $0 | -$0.18 |
The largest gap is content quality (-0.8), while clarity stays surprisingly close (-0.4). Ministral-3 3B produces readable prose but struggles with topic relevance. This might have to do with the individual article scoring that forms the basis for article selection - iterating the prompt or few-shot prompting there might thus improve the content quality.
Where Each Model Excelled
Crypto coverage was comparable. Both models scored 4/5 on content quality for "bitcoin, crypto markets, blockchain"—the local model's best result. For narrow, data-heavy topics with abundant news coverage, Ministral-3 3B performs well.
GPT-5.1 handled multi-topic briefs better. For "health, fitness, vegan diet," the cloud model covered plant-based diets, cholesterol, creatine, and sustainable eating habits (content: 4/5). The local model drifted toward general health policy—ACA subsidies, vaccine news—barely touching fitness or vegan content (content: 2/5).
Both models failed the same way on "AI, n8n." Neither mentioned n8n at all. The dominant term "AI" swallowed the niche one. GPT-5.1 produced polished AI coverage; Ministral-3 3B produced generic, sometimes speculative AI summaries with questionable source links.
Productivity was middling for both. For "productivity, habit building, deep work," both models covered morning routines and AI productivity tools—but neither explicitly addressed "deep work" as a concept. The local model produced duplicate content: two near-identical summaries about morning routines, two about AI productivity. GPT-5.1's output was more coherent but still scored only 3/5 on content quality.
Pattern observed: Ministral-3 3B tends to collapse onto the most frequent term in a topic set and underweight less common terms. "AI" dominates over "n8n"; "health" overshadows "vegan diet"; general productivity overshadows "deep work." This is a relevance scoring issue rather than a prose generation issue—improved prompts or few-shot examples in the scoring stage would likely help.
The Sourcing Problem
The local model's primary weakness was source attribution, not prose quality. Evaluator notes flagged:
- Placeholder links (
[Source](N/A)) in the finance newsletter - Suspicious URLs that didn't match standard article formats
- Numerical inconsistencies (e.g., citing a "66% drop" when the math suggested 50%)
GPT-5.1 consistently cited recognizable outlets (Wired, Bloomberg, Investopedia, Cointelegraph) with working links.
Runtime vs. Cost
At ~10 minutes per run, the local workflow is 6x slower but has zero marginal cost. The speed difference also stems from parallelism: OpenAI's API accepts concurrent requests across independent stages, while Ollama on a single MacBook processes requests sequentially.
GPT-5.1 costs roughly $0.18 per newsletter: ~60k input tokens x $1.25/M + ~10k output tokens x $10/M = $0.075 + $0.10 ≈ $0.18 (see OpenAI pricing).
For personal use or internal digests, the local model's cost advantage is significant at scale. For public-facing content where accuracy affects credibility, the cloud model's quality advantage may justify the cost.
Reliability
Neither setup is fully reliable. During testing, OpenAI's API was intermittently unreachable. The local pipeline had no network dependencies but failed more often on malformed JSON outputs (addressed by the auto-fix mechanism). The multi-stage n8n design accommodates both failure modes: retries can be added per stage, and models can be swapped without rewriting the workflow.
How to Run This Yourself
You can download the workflow here.
Prerequisites:
- n8n instance (self-hosted or cloud)
- Ollama running Ministral-3 3B Instruct for local mode
- OpenAI API key for cloud mode or evaluation judging
- SerpAPI credentials for DuckDuckGo News
- Tavily API key for research enrichment
- Telegram bot + chat ID for delivery
To adapt for your own topics:
- Edit the configuration node's topic list (e.g.,
machine learning,startups,TypeScript) - Adjust
minDaysBetweenandmaxDaysBetweento control newsletter frequency - Point the Model Selector to your preferred local or cloud model
For detailed setup instructions, see my posts on building an AI newsletter and the AI news agent.
Want a hosted version without running your own n8n? Contact me here.
Takeaways
Local models are viable—with the right architecture.
A 3B parameter model running on a MacBook produces readable, useful newsletters. The quality gap to GPT-5.1 is measurable but moderate: 3.47 vs 4.07 average score, with clarity scores close (4.2 vs 4.6). The techniques that enabled this
- task decomposition
- JSON auto-correction
- short context windows
are applicable to other local LLM workflows as well.
Content quality is the bottleneck, not writing ability.
Ministral-3 3B generates clear prose. Its weakness is editorial judgment: which articles matter, whether they match the brief, how to balance a multi-topic set. This can be targeted by adjusting the relevance scoring stage — improved prompts and few-shot examples might fix these deficiencies.
The evaluation setup enables iteration.
The multi-stage n8n design with built-in evaluation enables continuous improvement beyond this experiment. This allows swapping models, iterating prompts, and collecting human feedback—with relevant metrics measured automatically through the evaluation framework.